皆様こんにちは、価値ラボ株式会社の藤井です。主にRPAの導入支援やシナリオ作成代行を行っております。
今回は、RPAツールアシロボを使用して勤怠管理を自動化してみたいと思います。
RPAとアシロボについては過去記事で少しだけ説明しているのでご覧ください。
今回使用するシナリオはこちらからダウンロードできます。
勤怠管理表はこちらです。デスクトップに勤怠管理という名前のフォルダを作成してください。
以下の勤怠管理フォーマット.xlsxを、作成した勤怠管理フォルダに保存してください。
シナリオの内容
以下のような流れになっています。
- メールでアシロボに勤務時間を報告する
- アシロボが社員からのメールを受信する
- 受信したメールの内容を勤怠管理エクセルファイルに入力する
今回は初心者の方でもわかるように細かく解説しております。
総コマンド数が62個なので、今回はコマンドNo1~No37まで解説しています。No38~は次回のブログで解説したいと思います。
では、順に見ていきます。
まずは、メールでアシロボに勤務時間を報告します。
送信するメールのルールは以下の通りです。
(あくまでもこのシナリオでのルールです!)
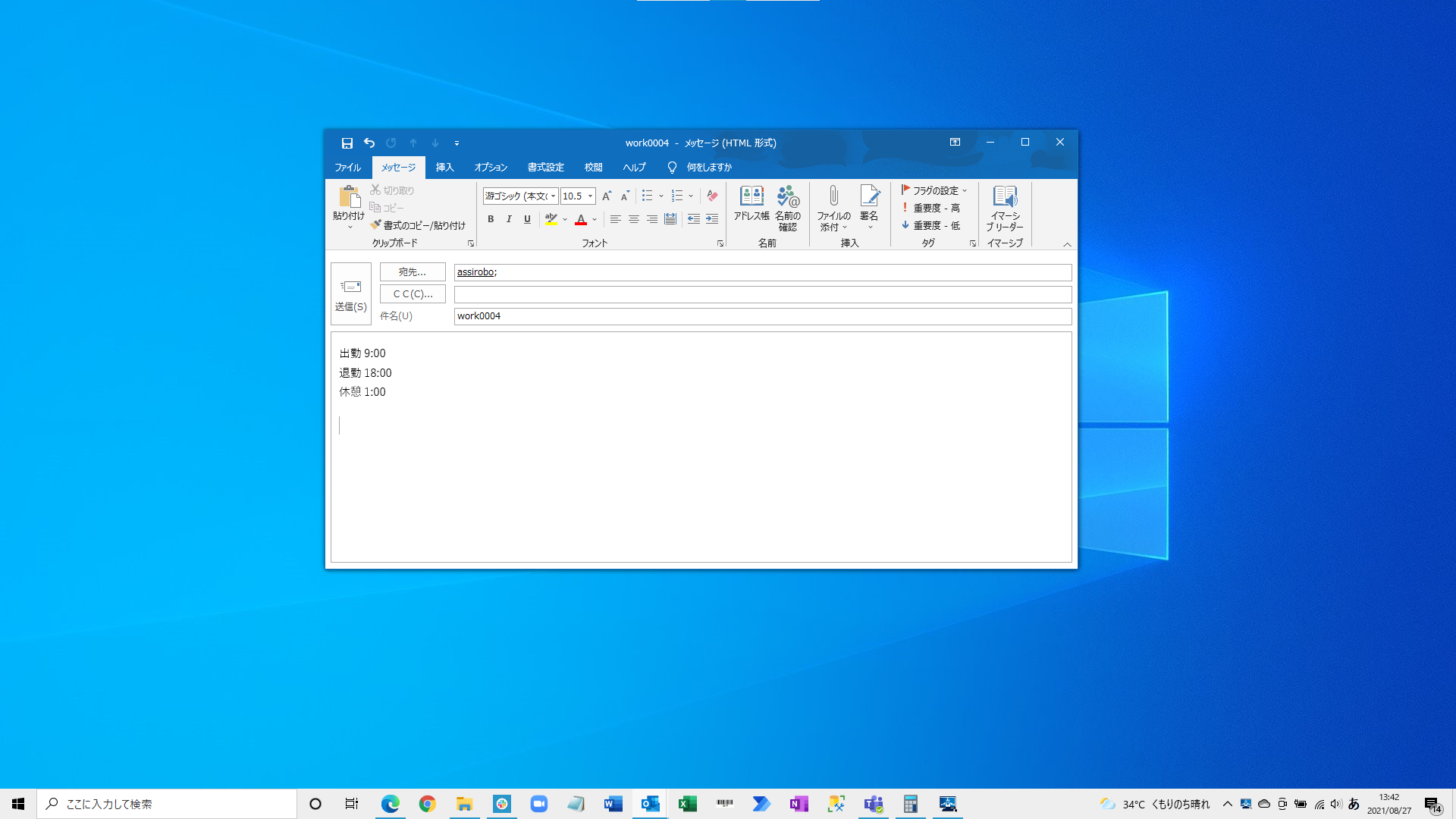
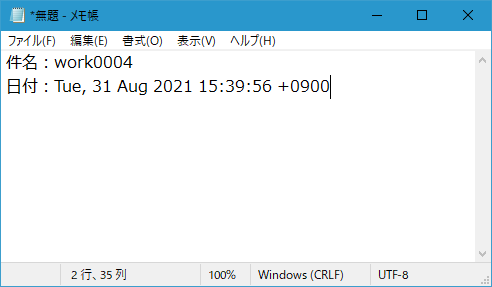
【件名】work0004
件名にworkが含まれているメールをアシロボが処理します。
別にworkである必要はありません。社員番号を入力する際に半角全角の切り替えが面倒なので英語にしました。
workingにするか悩みましたが、長いのでworkにしました。
そして、後ろの数字は社員番号です。社内に同姓同名の人がいる可能性があるので一意の値である社員番号にしました。
社員番号をもとに誰の勤怠管理表を開くか判断しています。
【本文】
出勤9:00
退勤18:00
休憩1:00
本文には出勤、退勤、休憩時間を入力します。
これをアシロボのアドレス宛に送信します。
そして、アシロボが社員番号0004の人から送られたメールを受信します。
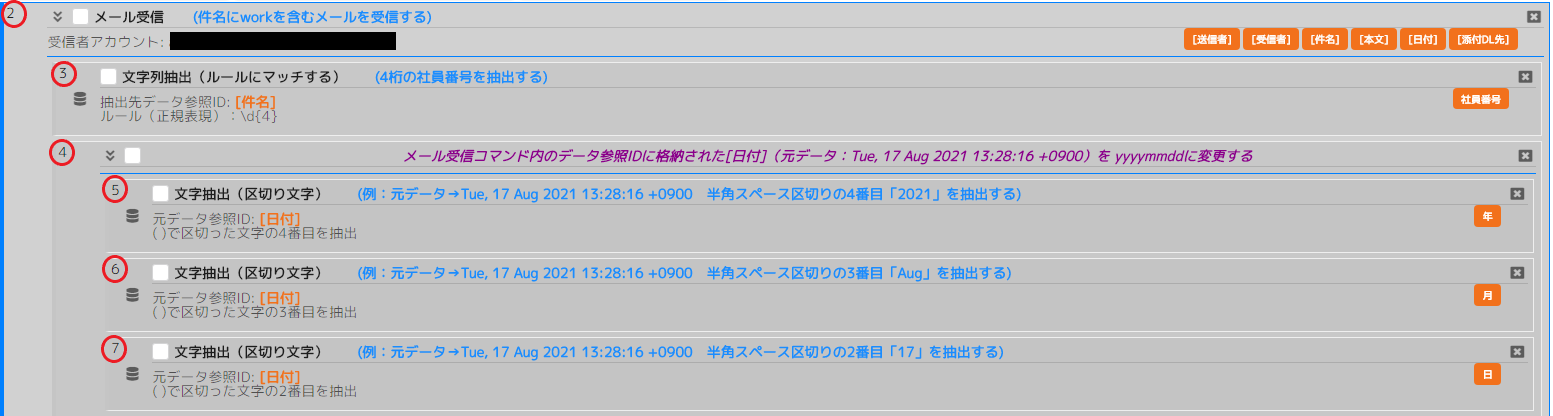
コマンドNoごとに説明します。(赤丸で囲った部分がコマンドNoです。)
No1 記憶(環境情報)
いきなり画像に載っていなくてごめんなさい。記憶(環境情報)コマンドでデスクトップを記憶しています。
No2 メール(受信)
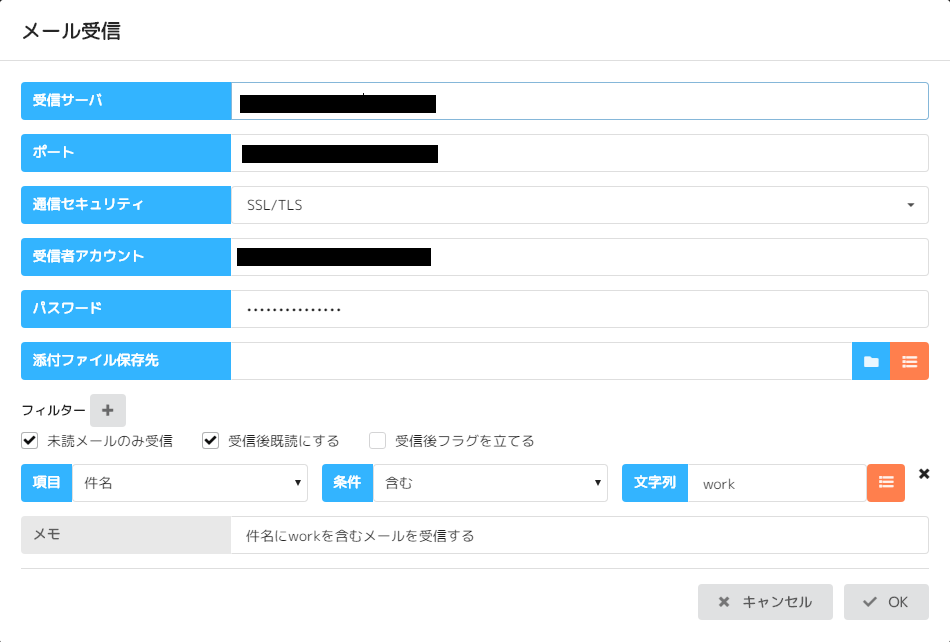
※実行する度にメールを送信するようになってしまうので、シナリオが完成するまでは「受信後既読にする」のチェックは外しておいた方がいいです!
メール受信コマンド内のデータ参照IDに格納されるものは、
[送信者]、[受信者]、[件名]、[本文]、[日付]、[添付DL先]です。
どのような形でデータ参照IDに格納されているのか確認しておきましょう。
確認の仕方
- アプリ起動コマンドでnotepad(メモ帳)を起動
- キーボード入力コマンドでメモ帳にデータ参照IDを書き出す
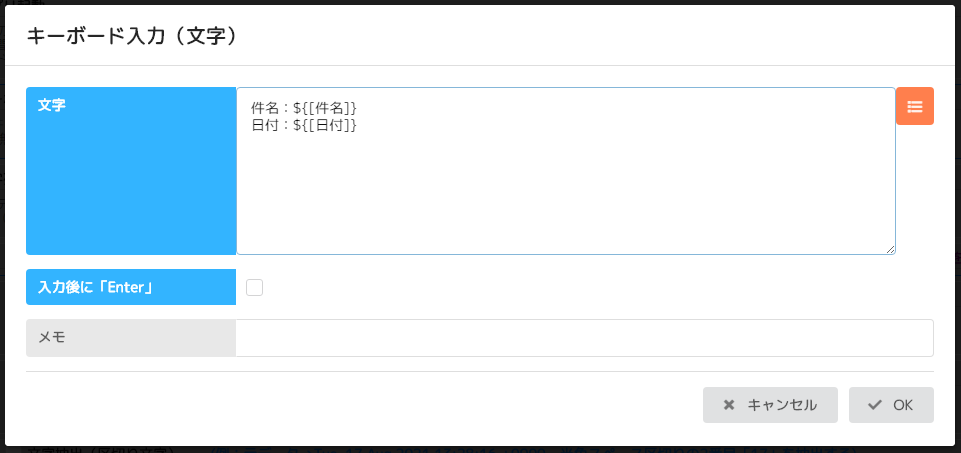

2,3,4のコマンドにチェックをいれて一部実行を行います。
今回のシナリオで使用するデータ参照ID([送信者]、[件名]、[本文]、[日付])の確認をしてください。
(ここではモザイク処理の必要がなさそうな件名と日付だけでご勘弁を。)
確認したら受信後行う処理を、メール受信コマンドの中に作成していきます。
※ここで使用した3,4のコマンドは削除して説明を続けます。
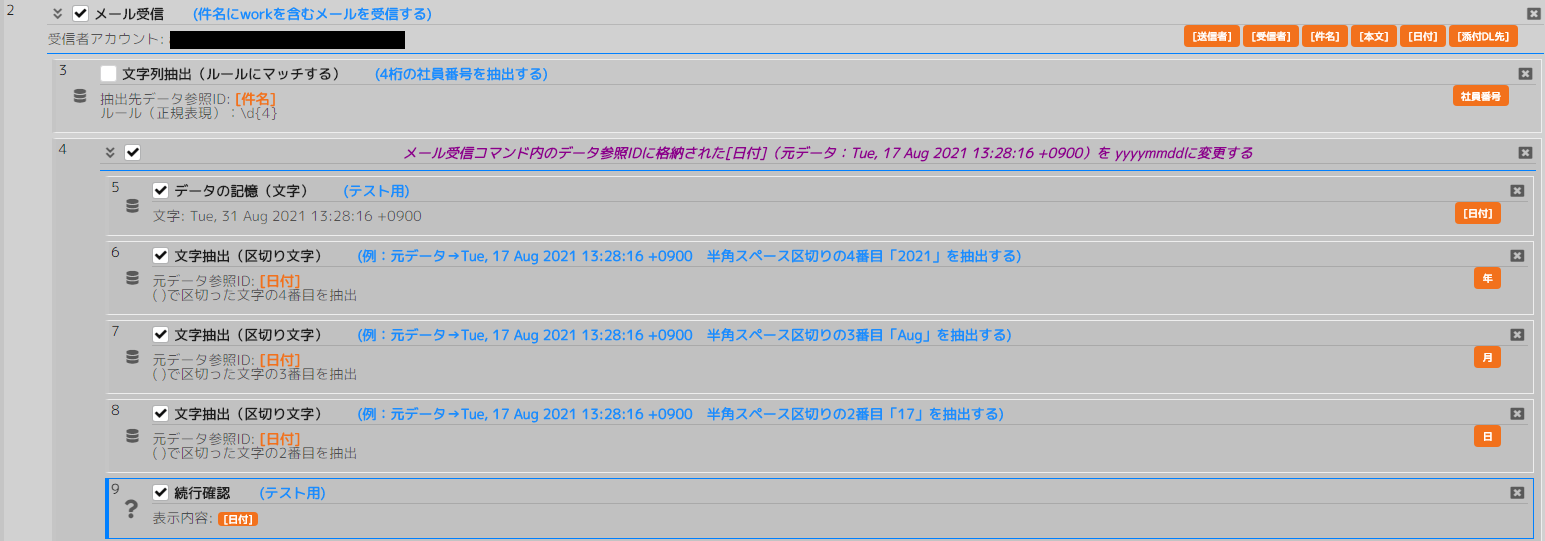
No3 文字抽出(ルールにマッチ)
(画像では抽出先データ参照ID:[件名]となっていますが、元データ参照IDの間違いです。修正してくれるそうです。)
元データ参照ID : [件名]
ルール(正規表現) : \d{4} (←4桁の数字を検索する正規表現)
抽出先データ参照ID : 社員番号
[件名] work0004 から4桁の数字を抽出。
抽出した値に社員番号という名前(抽出先データ参照ID)をつけます。
社員番号 = 0004
社員番号に0004という数字が格納されました。
No4 シナリオ整理(グループ化)
連続したコマンド群を一つのグループにしてまとめるコマンドです。
No5 文字抽出(区切り文字から)
[日付] = Tue, 31 Aug 2021 13:28:16 +0900
[日付]にはこのような形式で日付が格納されていることを確認済みです。
どうやら半角スペースで区切られているようです。
これを20210831にしたい場合は一旦、年、月、日にわけて取得します。
文字抽出(区切り文字)コマンドを使用して半角スペース区切りの4番目を抽出
1番目:Tue, 2番目:31 3番目:Aug 4番目:2021 5番目:13:28:16 6番目:+0900
抽出した値に年という名前をつけます。
年 = 2021
No6 文字抽出(区切り文字から)
3番目を抽出
月 = Aug
No7 文字抽出(区切り文字から)
2番目を抽出
日 = 31
このように文字抽出をした場合、思った通りの値が取得できているか実行するまでわかりません。
なので、実行する前にテストを行う方法を紹介します。
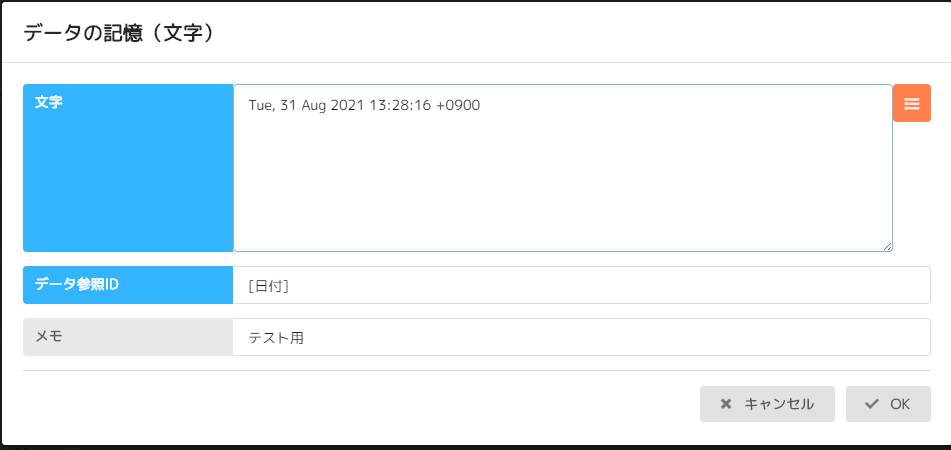
先ほどのコマンドNo5の前に記憶(文字)コマンドを追加します。
詳細はこのように設定します。
文字には、先ほどメモ帳に書き出した[日付]をコピーして貼り付けました。
データ参照IDはメール受信コマンド内の[日付]と同じ名前にします。(括弧は半角)
テスト用だとわかるようにメモを利用するといいと思います。
上の画像のように、3つある文字抽出コマンドの下に待機・終了・エラー>続行確認コマンドを追加します。
↓抽出したデータ参照ID(年、月、日)を表示内容に入力します。
(上の画像では表示内容が[日付]になっていますが、無視してください。)
オレンジのところをクリックして、表示したいデータ参照IDを選択すればOK。
見やすくするために「/」で区切っています。
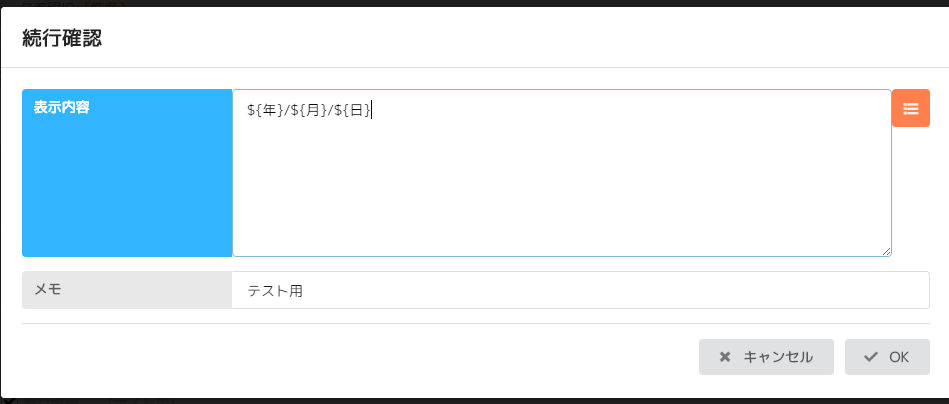
実行したい箇所にチェックをいれて、一部実行すると、、、
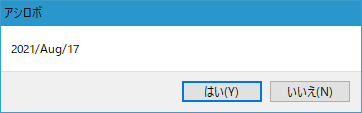
実行結果
続行確認コマンドの表示内容に入力したデータ参照IDの値が表示されました。
確認したら、いいえをクリックして処理を終了します。
狙い通りの値を取得できたことがわかりました。
テストに使用した5と9のコマンドは無効化しておきましょう。
(無効化ショートカットキー:無効化したいコマンドのコマンドNoの下にあるアイコンをクリック、コマンドを選択した状態にして、ctrl + Eで無効化。有効化する時も同じやり方です。)
次に月 = Augを数字に変換します。
分岐の文字列比較コマンドを使用して、
月がJanと一致するか文字列比較。
月がJanと一致した時は、1月。
一致しなかった時、月がFebと一致するか文字列比較。
月がFebと一致した時は、2月。
一致しなかった時、月がMarと一致するか文字列比較
月がMarと一致した時は、3月。
一致しなかった時、月がAprと一致するか文字列比較。
:
:
この作り方でも良かったのですが、長くなってしまうので、ちょっと変な(?)処理にしてみました。
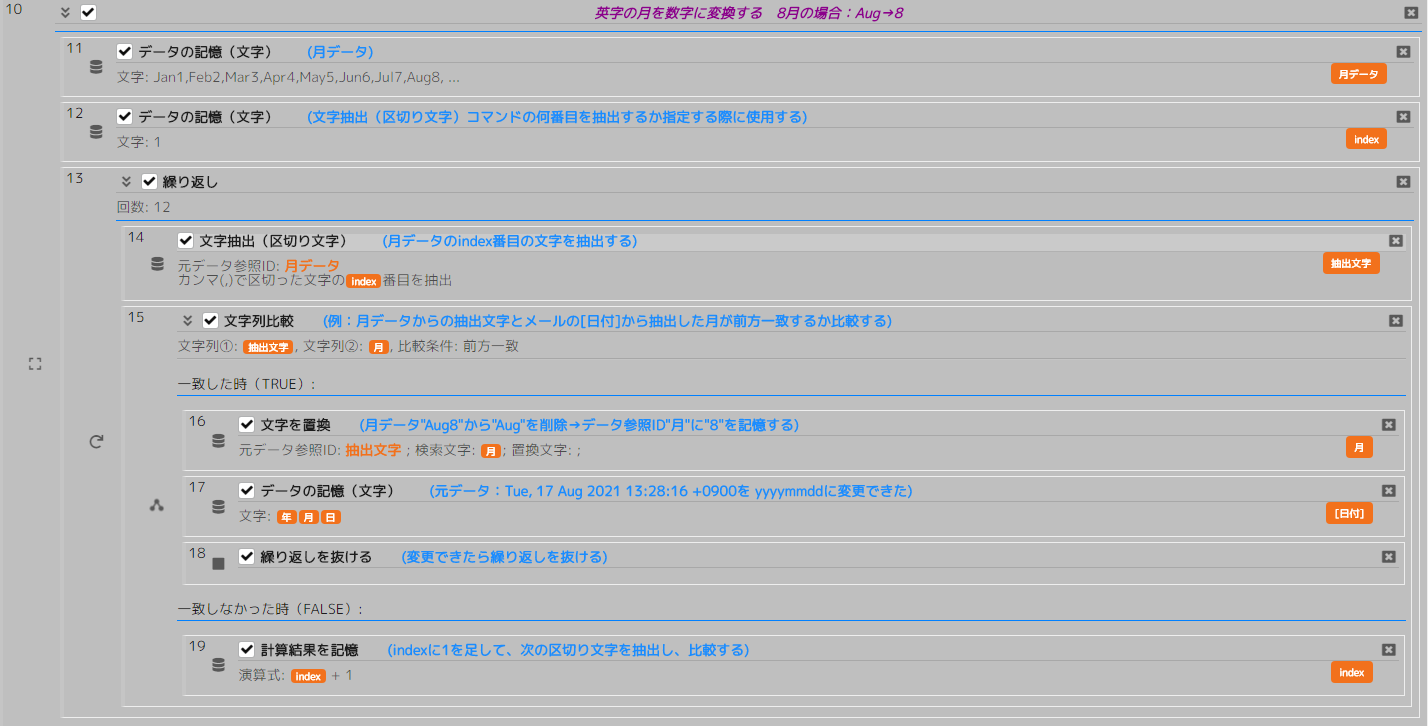
No11 記憶(文字)
以下のように、Jan1,Feb2,Mar3,…という感じで、文字を月データとして記憶します。
カンマ区切りです。配列のイメージです。(配列について知りたい方はこちら(わわわIT用語辞典)を参考にしてください。)
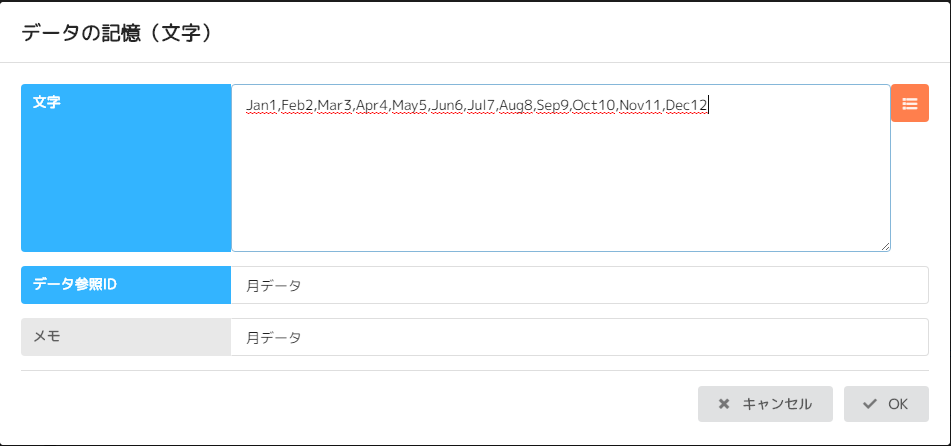
No12 記憶(文字)
データ参照ID「index」に半角の1を記憶します。
(プログラミングの配列の添字は0から始まりますが、アシロボの文字抽出(区切り文字)コマンドは1から始まるので注意です。)
No13 繰り返し(繰り返し)
繰り返しコマンドの中に処理を追加します。今回は月なので繰り返す回数は12回にしました。
No14 文字抽出(区切り文字から)
月データのカンマで区切ったindex番目(最初は1番目なのでJan1)の文字を抽出します。抽出した文字は抽出文字というデータ参照IDに格納。
No15 分岐(文字列)
抽出文字が月(この場合Aug)と前方一致するか比較します。
【一致した時】
No16 文字抽出(置換)
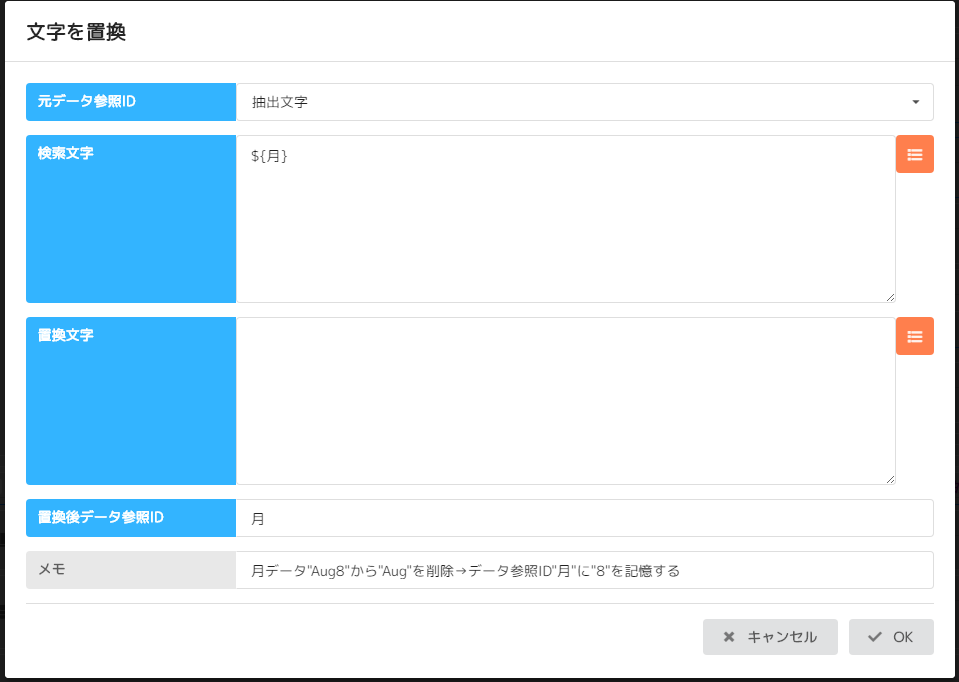
抽出文字(Aug8)から月(Aug)を検索し、空白と置換します。(Augを削除)
残ったのは8なので月に8が格納されます。
No17 記憶(文字)
文字に${年}${月}${日}と入力し、データ参照IDを[日付]とすれば、
元の[日付] = Tue, 31 Aug 2021 13:28:16 +0900が、
2021(年)8(月)31(日)→ 2021831になりました!
No18 繰り返し(繰り返しを抜ける)
目的を果たしたので繰り返しを抜けます。
【一致しなかった時】
No19 記憶(計算)
indexに1を足します。そして、データ参照IDは同じくindexとします。
index(最初は1)に1を足します、2になります。コマンドNo14に戻ります、index番目(2番目)を抽出します。
抽出文字(Feb2)と月(Aug)を比較します。一致しません、index(2)に1を足します、3になります。コマンドNo14に戻ります、index番目(3番目)を抽出します。
といった感じで一致するまで処理を繰り返します。
次は[本文]から出勤、退勤、休憩時間を抽出します。

No21 文字抽出(文字変換)
[本文]内の全角を半角に変換
9:00を9:00に統一したいな~と思って使用。
RPAはね、統一が大切ですからね。
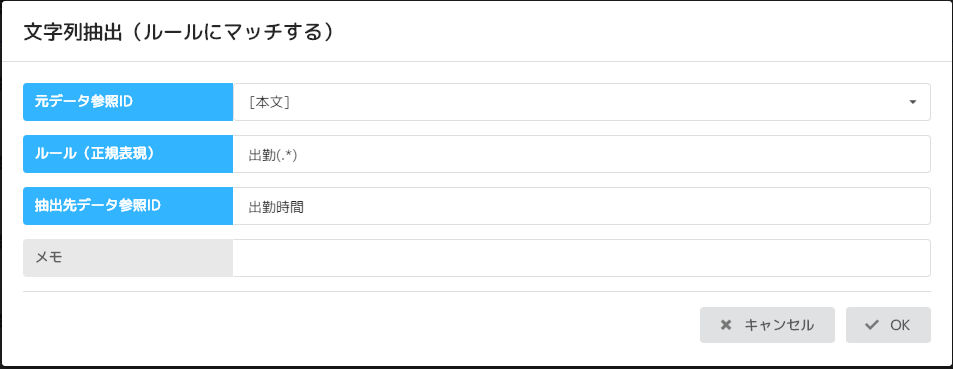
No22 文字抽出(ルールにマッチ)
[本文]から出勤という文字の後ろの文字列を抽出する。正規表現は画像を参考にしてください。
データ参照IDは出勤時間とする。
No23 文字抽出(改行・空白を削除)
抽出した出勤時間から余計な改行や、空白を削除する。
RPAはね、統一が大切ですから。
No24 文字抽出(ルールにマッチ)
出勤同様、退勤時間を抽出します。
No25 文字抽出(改行・空白を削除)
退勤時間から余計な改行や、空白を削除する。
No26 文字抽出(ルールにマッチ)
休憩時間を抽出します。
No27 文字抽出(改行・空白を削除)
休憩時間から余計な改行や、空白を削除します。
これで、本文から退勤時間、出勤時間、休憩時間を取得することができました。
ここで一旦、使用するデータ参照IDを整理しましょう。
[送信者] = 社員さんのメールアドレス
社員番号 = 0004
出勤時間 = 9:00
退勤時間 = 18:00
休憩時間 = 1:00
[日付] = 2021831
よし。
No28 分岐(ファイル・フォルダの有/無を確認)
続いて、勤怠管理フォルダのなかに社員番号、今回は0004という名前のファイルがあるか確認します。
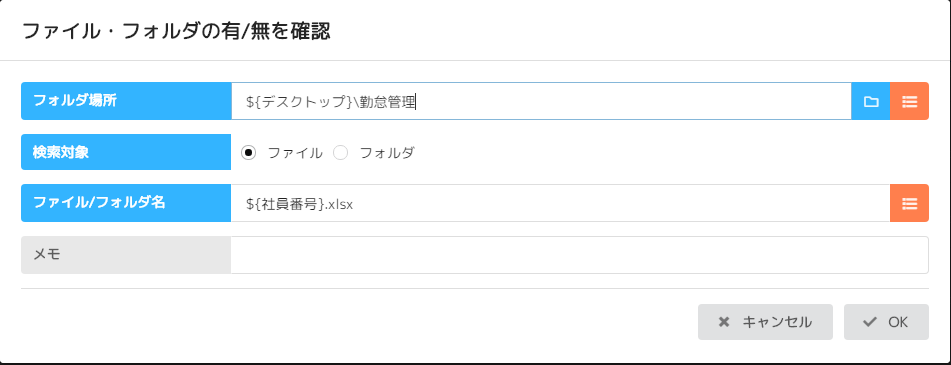
デスクトップにある勤怠管理フォルダに0004.xlsxというファイルがあるか確認します。
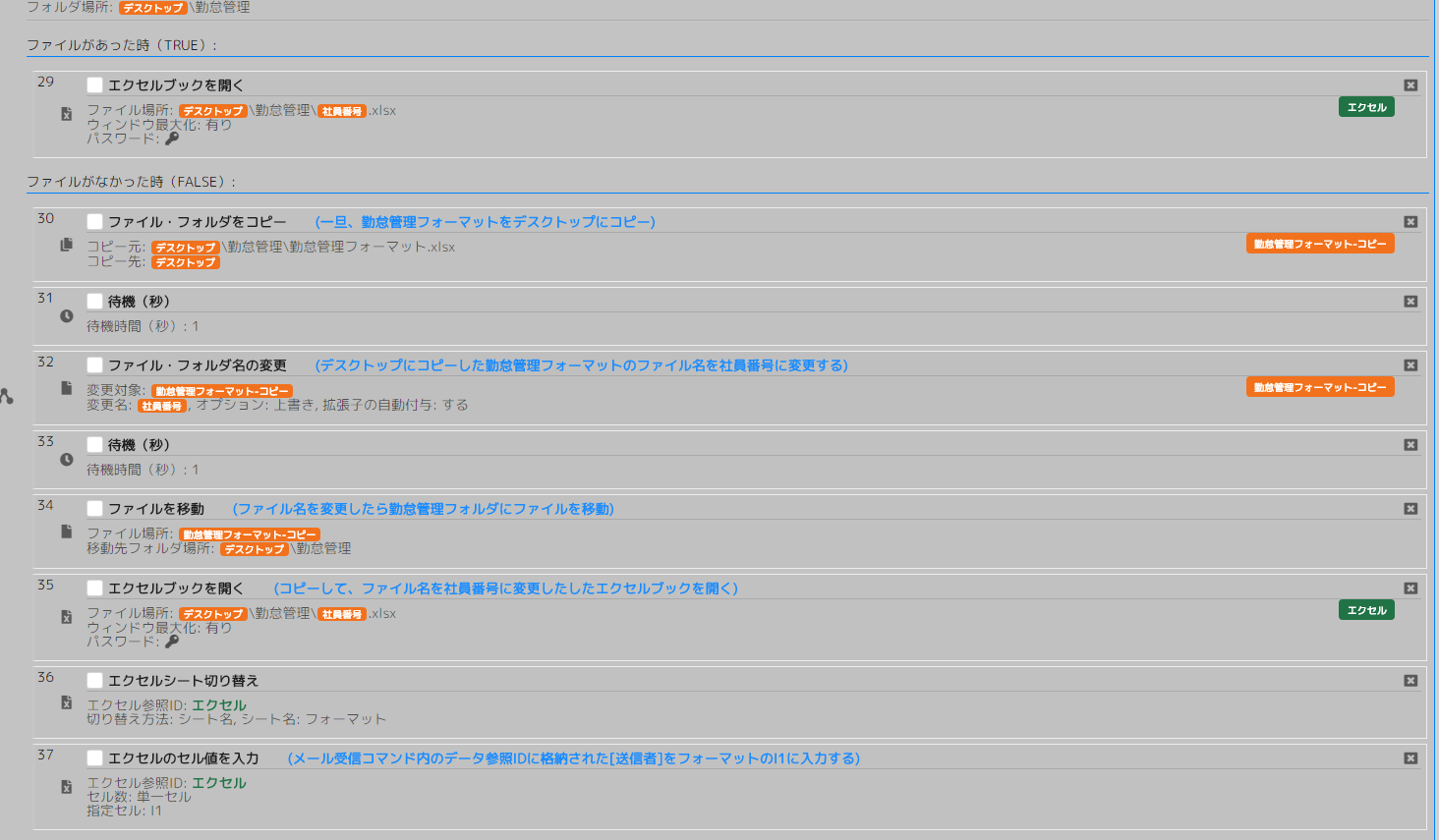
【ファイルがあった時】
No29 エクセル・CSV(ブック>ブックを開く)
デスクトップ\勤怠管理\0004.xlsxを開く。
【ファイルがなかった時】
No30 ファイル・フォルダ(ファイル・フォルダをコピー)
デスクトップ\勤怠管理\勤怠管理フォーマット.xlsxをデスクトップにコピーする。
コピーしたファイルに「勤怠管理フォーマット-コピー」というデータ参照IDを付ける。
デスクトップ\勤怠管理フォーマット.xlsx(データ参照ID:勤怠管理フォーマット-コピー)
No31 待機・終了・エラー(秒)
1秒待機
No32 ファイル・フォルダ名の変更
データ参照ID3515e7勤怠管理フォーマット-コピーのファイル名を社員番号に変更する。
デスクトップ\勤怠管理フォーマット.xlsx → デスクトップ\0004.xlsx
No33 待機・終了・エラー(秒)
1秒待機
No34 ファイル・フォルダ(移動)
デスクトップ\0004.xlsx → デスクトップ\勤怠管理\0004.xlsx
No35 エクセル・CSV(ブック>ブックを開く)
デスクトップ\勤怠管理\0004.xlsxを開く。
No36 エクセル・CSV(シート操作>切り替え)
シート名:フォーマットに切り替える。
No37 エクセル・CSV(セル操作>値を入力)
メール受信コマンド内のデータ参照IDに格納された[送信者]をフォーマットのL1に入力する

この勤怠管理表が送信者の勤怠管理表であることを確認するためにフォーマットに送信者の情報を入力しておきます。
長くなってしまうので今回の解説はここまでです。No38~は次のブログで解説したいと思います。
お疲れ様でしたm(_ _)m☆
最後までご覧いただきありがとうございます。
お役に立てれば幸いです。



